Last time out, we determined that mucking with the estimate to account for variance and surprises in projects is in several ways wanting. This time, we’ll make some choices about the tasks and the projects, and see where those choices might take us.
Leave Problem Tasks Incomplete; Accept Missing Features
There are a couple of variations on this strategy. The first is to Blow The Whistle At 100. That is, we could time-box the entire project, which in the examples above would mean stopping the project after 100 hours of work no matter where we were. That might seem a little abrupt, but we would be done after 100 hours.
To reduce the surprise level and make things a tiny bit more predictable, we could Drop Scope As You Go. That is, if we were to find out at some point that you’re behind our intended schedule, we could refine the charter of the project to meet the schedule by immediately revising the estimate and dropping scope commitments equivalent to the amount of time we’ve lost. Moreover, we could choose which tasks to drop, preferring to drop those that were interdependent with other tasks.
In our Monte Carlo model, project scope is represented by the number of tasks that we attempt. After a Wasted Morning, we drop any future commitment to at least three tasks; after a Lost Day, we drop seven; and after a Black Cygnet, we drop 15. We don’t have to drop the tasks completely; if we get close to 100 hours and find out that we have plenty of time left over due to a number of Stunning Successes, we can resume work on one or more of the dropped tasks.
Of course, any tasks that we’ve dropped might have turned out to be Stunning Successes, but in this model, we assume that we can’t know that in advance; otherwise, there’d be no need to estimate. In this scenario, it would also be wise to allocate some task time to manage the dropping and picking up of tasks.
I’ve been a program manager for a company that used a combination of Blow The Whistle and Drop Scope As You Go very successfully. This strategy often works reasonably well for commercial software. In general, you have to release an update periodically to keep the stock market analysts and shareholders happy. Releasing something less ambitious than you hoped is disappointing. Still, it’s usually more palatable than shipping late and missing out on revenue for a given quarter. If you can keep the marketers, salespeople, and gossip focused on things that you’ve actually done, no one outside the company has to know how much you really intended to do. There’s an advantage here, too, for future planning: uncompleted tasks for this project represent elements of the task list for the next project.
Leave Problem Tasks Incomplete; Accept Missing Features AND Bugs
We could time-box our tasks, lower our standard of quality, and stop working on a task as soon as it extends beyond a Little Slip. This typically means bugs or other problems in tasks that would otherwise have been Wasted Mornings, Lost Days, or Black Cygnets, and it means at least a few dropped tasks too (since even a Little Slip costs us a Regular Task).
This is The Perpetual Beta Strategy, in which we adjust our quality standards such that we can declare a result a draft or a beta at the predicted completion time. The Perpetual Beta Strategy assumes that our customers explicitly or implicitly consent to accepting something on the estimated date, and are willing to sacrifice features, live with problems, wait for completion of the original task list, or some combination of all of these. That’s not crazy. In fact, many organizations work this way. Some have got very wealthy doing it.
Either of these two strategies would work less well the more our tasks had dependencies upon each other. So, a related strategy would be to…
De-Linearize and Decouple Tasks
We’re especially at risk of project delays when tasks are interdependent, and when we’re unable to switch the sequence of tasks quickly and easily. My little Monte Carlo exercises are agnostic about task dependencies. As idealized models, they’re founded on the notion that a problem in one area wouldn’t affect the workings in any other area, and that a delay in one task wouldn’t have an impact on any other tasks, only on the project overall. On the one hand, the simulations just march straight through the tasks in each project equentially, as though each task were dependent on the last. On the other hand, each task is assigned a time at random.
In real life, things don’t work this way. Much of the time, we have options to re-organize and re-prioritize tasks, such that when a Black Cygnet task comes along, we may be able to ignore it and pick some other task. That works when we’re ultimately flexible, and when tasks aren’t dependent on other tasks.
And yet at some point, in any project and any estimation effort there’s going to be a set of tasks that are on a critical path. I’ve never seen a project organized such no task was dependent on any other task. The model still has some resonance, even if we don’t take it literally.
A key factor here would seem to be preventing problems, and dealing with potential problems at the first available opportunity.
Detect and Manage The Problems
What could we do to prevent, detect, and manage problems?
We could apply Agile practices like promiscuous pairing (that is, making sure that every team member regularly pairs with every other team member). Such things might to help with the critical path issue. If each person has at least passing familiarity with the whole project, each is more likely to be able to work on a new task while their current one is blocked. Similarly, when one person is blocked, others can help by picking up on that person’s tasks, or by helping to remove the block.
We could perform some kind of corrective action as soon as we have any information to suggest that a given task might not be completed on time. That suggests shortening feedback loops by constant checking and testing, checking in on tasks in progress, and resolving problems as early as possible, instead of allowing tasks to slip into potentially disastrous delays. By that measure, a short daily standup is better than a long weekly status meeting; pairing, co-location and continuous conversation are better still. Waiting to check or test the project until we have an integration- or system-level build provided relatively slow feedback for low-level problems; low-level unit checks reveal information relatively quickly and easy.
We could manage both tasks and projects to emphasize information gathering and analysis. Look at the nature of the slippages; maybe there’s a pattern to Black Cygnets, Lost Days, or Wasted Mornings. Is a certain aspect of the project consistently problematic? Does the sequencing of the project make it more vulnerable to slips? Are experiments or uncertain tasks allocated the task time that they need to inform better estimation? Is some person or group consistently involved in delays, such that training, supervision, pairing, or reassignment might help?
Note that obtaining feedback takes some time. Meetings can take task-level units of times, and continuous conversation may slow down tasks. As a result, we might have to change some of our tasks or some part of them from work to examining work or talking about work; and it’s likely some Stunning Successes will turn into Regular Tasks. That’s the downside. The upside is that we’ll probably prevent some Little Slips, Wasted Mornings, Lost Days and Black Cygnets, and turn them into Regular Tasks or Stunning Successes.
We could try to reduce various kinds of inefficiencies associated with certain highly repetitive tasks. Lots of organizations try to do this by bringing in continuous building and integration, or by automating the checking that they do for each new build. But be aware that the process of automating those checks involves lots of tasks that are themselves subject to the same kind of estimation problems that the rest of your project must endure.
So, if we were to manage the project, respond quickly to potentially out-of-control tasks, and moderate the variances using some of the ideas above, how would we model that in a Monte Carlo simulation? If we’re checking in frequently, we might not be able to get as much done in a single task, so let’s turn the Stunning Successes (50% of the estimated task time) into Modest Successes (75% of the estimated task time). Inevitably we’ll underestimate some tasks and overestimate others, so let’s say on average, out of 100 tasks, 50 come in 25% early, 49 come in 25% late. Bad luck of some kind happens to everyone at some point, so let’s say there’s still a chance of one Black Cygnet per project.
| Number of tasks | Type of task | Duration | Total (hours) |
|---|---|---|---|
| 50 | Modest Success | .75 | 37.5 |
| 49 | Tiny Slip | 1.25 | 61.25 |
| 1 | Black Cygnet | 16 | 16 |
Once again, I ran 5000 simulated projects.
| Average Project | 114.67 |
| Minimum Length | 92.0 |
| Maximum Length | 204.25 |
| On time or early | 1058 (21.2%) |
| Late | 3942(78.8%) |
| Late by 50% or more | 96 (1.9%) |
| Late by 100% or more | 1 (0.02%) |
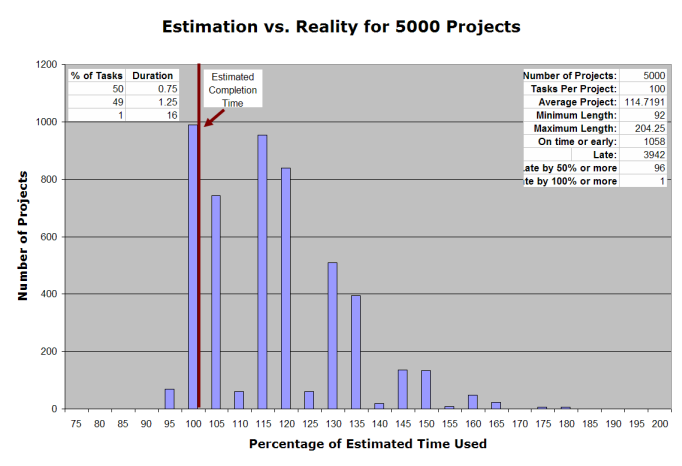
Remember that in the first example above, half our tasks were early by 50%. Here, half our tasks are early by only 25%, but things overall look better. We’ve doubled the number of on-time projects, and our average project length is down to 114% from 124%. Catching problems before they turn into Wasted Mornings or Lost Days makes an impressive difference.
Detect and Manage The Problems, Plus Short Iterations
The more tasks in a project, the greater the chance that we’ll be whacked with a random Black Cygnet. So, we could choose your projects and refrain from attempting big ones. This is essentially the idea behind agile development’s focus on a rapid series of short iterations, rather than on a single monolithic project. Breaking a big project up into sprints offers you the opportunity to do the project-level equivalent of frequent check-ins in on our tasks.
When I modeled an agile project with a Monte Carlo simulation, I was astonished by what happened.
For the task/duration breakdown, I took the same approach as just above:
| Number of tasks | Type of task | Duration | Total (hours) |
|---|---|---|---|
| 50 | Modest Success | .75 | 37.5 |
| 49 | Tiny Slip | 1.25 | 61.25 |
| 1 | Black Cygnet | 16 | 16 |
I changed the project size to 20 tasks. Then, to compensate for the fact that the projects were only 20 tasks long, instead of 100, I ran 25000 simulated projects.
| Average Project | 22.94 |
| Minimum Length | 16 |
| Maximum Length | 66.75 |
| On time or early | 12433 (49.7%) |
| Late | 12567 (50.3%) |
| Late by 50% or more | 4552 (18.2%) |
| Late by 100% or more | 400 (1.6%) |
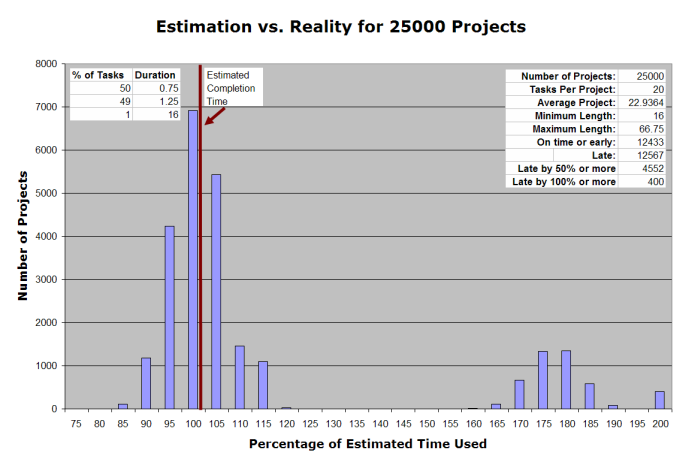
A few points of interest. At last, we’re estimating to the point where almost half our the projects are on time! In addition, more than 80% of the projects (20443 out of 25000, in my run) are within 15% of the estimate time—and since the entire project is only 20 hours, these projects run over by only three hours. That affords quick course correction; in the 100-hours-per-project model, the average project is late by three days.
Here’s one extra fascinating result: the total time taken for these 25000 projects (500,000 tasks in all) was 573,410 hours. For the original model (the one above, the first in yesterday’s post), the total was 619,156.5 hours, or 8% more. For the more realistic second example, the total was 736,199.2 hours, or 28% more. In these models, shorter iterations give less opportunity for random events to affect a given project.
So, what does all this mean? What can we learn? Let’s review some ideas on that next time.
I nearly applauded when I read this:
“Releasing something less ambitious than you hoped is disappointing. Still, it’s usually more palatable than shipping late and missing out on revenue for a given quarter. If you can keep the marketers, salespeople, and gossip focused on things that you’ve actually done, no one outside the company has to know how much you really intended to do.”
That is a statement that is so overlooked in our industry. It’s really easy to get beaten down as a project team by those within an organization who dwell on what you didn’t get done vs. what you delivered.
As for what can we learn from this series, I think that we can see that by breaking down a “mega-project” into several “mini-projects” we are better able to estimate, provide feedback, and correct course much more efficiently. The often said point regarding the cost of fixing and issue early in a project vs. late in the game clearly comes to light here as well.
Another benefit in breaking into shorter iterations is we get better at our estimates. After finishing a sprint, we should have a good idea of how long it took us to complete our critical path tasks. If we have to perform the same tasks again, we should be able to provide a more accurate estimate based on historical experience rather than our best guess. Of course there still will be fluctuations but we can have a better degree of confidence in them.
Michael replies: Alas we never really perform exactly the same tasks when we’re creating new solutions to new problems, but your point is well taken: we can choose to learn to be humble about what we can accomplish, and flexible when we don’t get done everything we had hoped.
Great series of posts, by the way. I get a lot out of your blog.
Cheers,
Rich
Thanks for the kind words and helpful points, Rich.
Hi Michael,
From a team’s perspective, it isn’t possible for the team to produce more work by dividing a 100 task project into 5 projects with 20 tasks each. The overhead of tools up and tools down between projects means that the team will produce less than the 100 tasks if they split the project into 5 projects.
Michael replies: That’s possible, on the assumption that the tasks aren’t interdependent; that there’s enough flexibility on the team to deal with Black Cygnets or lesser surprises. You’d also have to account for the overhead of co-ordinationg between people.
I also believe events that results in lost days will happen at the same frequency regardless of how many tasks is in a project.
Surely that depends on the causes of the Lost Days, and what they affect—the task, or the project, or all of the concurrent projects as you’ve suggested above. If the Lost Days come from the world outside, then they’ll happen at the same random rate at which that they normally happen. If they affect an individual task or project, that’s not such a big deal. But some Black Swans affect entire companies, business sectors, countries… What’s most interesting to me is the effect that comes from shortening the tasks in Part 3. I recognize that the model is highly unrealistic, as I emphasize here. Remember, it’s designed to provoke questions and conversations, not guide decisions.
The best way to combat time lost is to ensure that tasks are as little resource dependent as possible. Multi-skilled staff can greatly reduce your losses.
I agree with that, in general. Still, that’s an ideal. Some things stand to benefit more from specialization; others stand to lose more from it.
The benefit of having 5 projects is that you can deliver more frequently and show results sooner. The drawback is that if your first project is late, the next 4 projects will also be late, so you have to face the music 5 times now, instead of just once.
I think you’re suggesting that we stick to a plan that the evidence (from the first project) suggests was less than completely achievable. On the other hand, if you use what you’ve learned from that first project, you might be able to scale back your expectations in a pragmatic way. More frequent feedback gives more frequent opportunities to adjust.
Regards,
Leonard.
Thanks for the comment.
[…] work in a short and predictable amount of time. If we need to change course because of some unexpected event, we don’t have to scrap the foundations of work that won’t be complete for months, we only have […]