In the last post, I talked about the asymmetry of unexpected events and the attendant problems with estimation. Today we’re going to look at some possible workarounds for the problems. Testers often start by questioning the validity of models, so let’s start there.
The linear model that I’ve proposed doesn’t match reality in several ways, and so far I haven’t been very explicit about them. Here are just a few of the problems with the model.
- The model tacitly assumes that all tasks have to be done in a specific order.
- The model tacitly assumes that all tasks are of equal significance.
- The model leaves out all notions of tasks being independent or interdependent with respect to each other.
- The model assumes that once we’re into a Wasted Morning, a Lost Day, or a Black Cygnet, there’s nothing we can do about it, and that we won’t do anything about it.
In particular, the model leaves out control actions that could be applied by managers or by the people performing the tasks, control actions that could be applied to the tasks, the project, the context, or to the estimates. Let’s start with the latter.
Pad The Estimates So We’re Half Right
Here’s the chart of yesterday’s first scenario again:
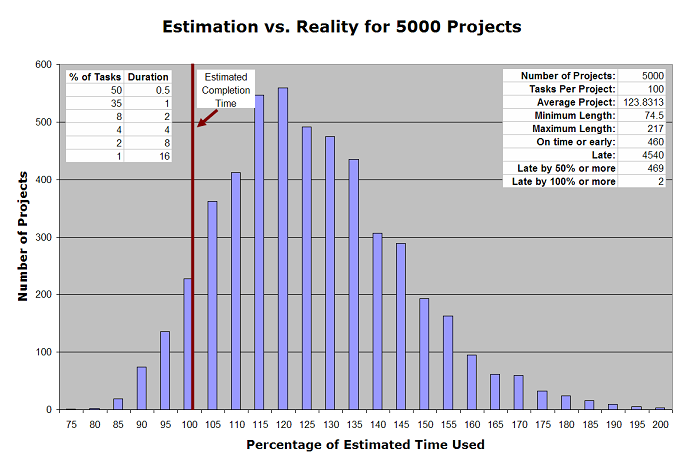
Under the given set of assumptions, and assuming random distribution, we come in late a little over 90% of the time. To counter this, we could add some arbitrary percentage to our estimates such that half the time we’ll come in early, while the other half of the time we’ll (still) come in late. In that case, we’d want to pick a median value.
When I used the data from the Monte Carlo simulation and sorted the project lengths, I found that Project 2500, the one right in the middle, has a length of 122 hours. So: pad the estimate by 22%, and we’ll be on time 50% of the time.
There are two problems with this. The first is that there’s still significant variability in terms of how late. Second, the asymmetry problem is the same for projects as it is for individual tasks: our big losses have a greater magnitude than our big wins. Even if we go for the average project length, rather than the median (the average 123.83 hours, is a couple of hours longer), fewer projects will go over the estimated time, but early projects will tend to be more modestly early, while the late ones will be more extremely late. None of this is likely to be acceptable to someone who values predictability (that is, the person who is asking us for the estimate).
Pad The Estimates So We’re Almost Always Right
Someone who likes predictability would probably prefer our projects to come in on time 95% of the time. If we wanted to satisfy that, based on the same set of assumptions, we would do the best estimating job we could, then pad our estimate by 58%, to 158 hours.
One problem with that strategy is that work tends to expand to fill time available, and people will start to work at a slower pace.
One the other hand, if people keep the regular pace up, 82% of our projects are going to come in at least 10% early, and 42% of our projects will come in 25% early! In such a case, we’ll probably face political backlash and be urged to less conservative with our estimates. By the math, we really can’t win under this set of assumptions.
Pad The Team
Rather than padding the estimate of time, we could build slack into the system by having extra people available to take on any surprises or misunderstandings. But note Fred Brooks’ Law, which says that adding people to a late project makes it later. That’s because of at least two problems: the new people need to be brought up to speed, and having more connections in a system tends increases the communication burden.
So maybe we’ll have to change something about the way we manage the project. We’ll look at that next.
You may want to hint out that both, Jerry Weinberg as well as Alistair Cockburn, showed that Brook’s Law does not only hold for late projects, but for any project when it comes to the complexity among the number of people involved. You assume this, but maybe the connection to some readers is missing in the last paragraph.
Great article! Certainly the pacing explanation. Most projects don’t take place in a vacuum, there are parallel tasks or projects or other surrounding work influencing the pace people can work at too, throwing estimates off even further because of time lost in switching contexts (almost always underestimated or ignored).
Michael – I was just searching for blogs and books on estimation and just found this entry. I like your idea of padding the team capability to account for potential black swans. One interesting thought experiment that I have used in the past is to use what I call a non-linear “50-50” analysis. At the start of the project or task, perform a thought experiment of how to accomplish the work in 50% of the scheduled time and with 50% of the resources (understanding that the result would be at high risk of failing). Then at the 50% mark, repeat it for the remaining schedule and resources. And so on …
The big problem is that if you present this analysis in a hierarchical organization to the customer, management, or coworkers then they tend to pad their expectations likewise and the benefit of the analysis falls apart. It works better with small teams where you can gain a tacit understanding that what you are searching for is potential *positive* black swans to help offset the potential negative ones. It also helps keep the team focused on the goal and not the original estimated schedule.
Michael replies: You might enjoy Taleb’s new book, Antifragile, which has a lot to say about this. What you’re talking about sounds like a barbell strategy to some degree.