The previous post in this series was something of a diversion from the main thread, but we’ll get back on track in this long-ish post. To review: Marshall McLuhan famously said that “the medium is the message”. He used this snappy slogan to point out that media, tools, and technologies are not only about what they contain; they’re also about themselves, changing the scale, pace, or pattern of human affairs and activities. As he somewhat less famously said, “We shape our tools; thereafter, our tools shape us.”
In the Rapid Software Testing namespace, we recognize the traditional interpretation of an oracle in software testing as “an external mechanism which can be used to check test output for correctness”. W.E. Howden, who introduced the term, said that oracles “can consist of tables, hand calculated values, simulated results, or informal design and requirements descriptions”. But after recognizing that interpretation, we offer a more general and, to us, a more useful notion of “oracle”: a means by which we recognize a problem when we encounter one during testing.
We also make a distinction between testing and checking. Testing is the process of evaluating a product by learning about it through exploration and experimentation, which includes to some degree: questioning, study, modeling, observation, inference, etc. Checking is the process of making evaluations by applying algorithmic decision rules to specific observations of a product. A check produces a bit—true or false, green or red, pass or fail. A check is a kind of formal testing; testing that is done is a specific way, or with the goal of determining specific facts. Checking is a tactic of testing, but it’s certainly not all there is to testing.
In that light, Howden’s examples of oracles—references—form bases for checks. Add McLuhan’s insights, and we can recognize that checks are media that extend and accelerate our capacity to observe inconsistency with a specific claim (“the product, given these inputs, should produce output consistent with the values in this table”), or with a comparable product (“the product, given this inputs, should produce output consistent with the values produced by this simulator”).
So: automated checks are media that extend and accelerate our capability to observe and evaluate the product in accordance with explicit, algorithmic decision rules.
Why is all this a big deal?
One: because media don’t recognize problems; media extend, enhance, enable, accelerate, intensify, or amplify our capability to recognize problems.
My friend Pradeep Soundararajan attracted my attention and respect several years ago by this astute observation: “It is not a test that finds a bug; it is a human that finds a bug and a test plays a role in helping the human find it.” To paraphrase Pradeep, the tool doesn’t recognize the problem; the tool plays a role in recongnizing the problem.
The microscope does not see; the microscope helps us to see. The burglar alarm doesn’t detect a burglary; the burglar alarm extends our senses over distance to recognize movement, whereby we can infer that a burglary might be happening.
The Wikipedia entry Exploration of Mars errs by saying “The exploration of Mars is the study of Mars by spacecraft.” In fact, the exploration of Mars is the study of Mars by humans, enabled by spacecraft.
Tools amplify whatever we are. Tools can extend people’s competence and capabilities to help them focus on what matters, allowing them to become aware of important new things. Tools can just as easily extend people’s incompetence and incapabilities to overfocus their attention on the known or the trivial, allowing them to be oblivious to important things.
Two: because tools can do so much more for testers than automated checking.
Testing is not simply checking to determine whether we’re getting the right answers. Testing is also about making sure we’re asking important questions—and discovering important questions, and discovering things about how we might develop and apply checks.
For instance: my colleague James Bach was working on testing a medical device a few years back. I’ve done some work with this company too, so in order to respect non-disclosure agreements, let’s just say that the medical device is a Zapper Box, intended to deliver Healing Energy to a patient’s body over an Appropriate Period of Time. The Zapper Box is controlled by a Control Box and its software.
Too much of a Good Thing can be a Very Bad Thing so, crucially, the Control Box is also intended to stop the Zapper Box from delivering that energy when the Appropriate Period of Time becomes an Inappropriate Period of Time, whereupon the Healing Energy becomes Killing Energy.
The Control Box has a display that shows the operator the amount of Healing Energy that is supposedly being delivered. James and one of the other testers set up a test rig, a meter to monitor the amount of Healing Energy that was actually being delivered.
In one of the tests, they monitored and logged the amount of Healing Energy delivered after the device’s operator turned off the Healing Energy Tap via the Control Box. The log recorded measurements at intervals of one-tenth of a second. The testers did several hundred instances of this test.
Then James took the logs, and used Microsoft Excel’s conditional formatting feature to highlight various levels of Healing Energy. Red indicated that the device was delivering Energy that could be described here as Very Hot; yellow represented Somewhat Hot; grey represented Cooling Down; green represented Cool. Then, James took over a hundred lines of data, and shrank the lines down until the numbers were too small to see, such that only two digits are readable: the numbers 1 and 2 labelling the vertical lines, which represent the one- and two-second marks after the Healing Energy Tap had been turned off. In Rapid Software Testing we call this a Blink Test, or using a Blink Oracle. Here’s what the testers saw:
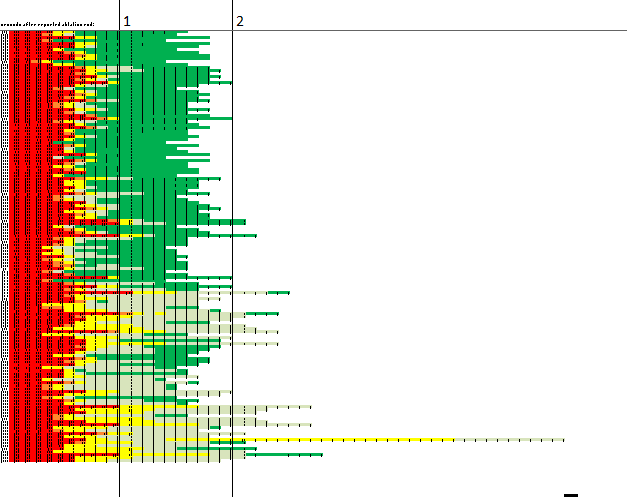
What do you observe? Here’s what I observe:
- Over about 150 test runs, the level of Energy appears to remain Very Hot for .3 seconds to over a second after the Healing Energy Tap was turned off.
- Towards the end of the observed period, the device seems to remain in a Very Hot state for longer, and more often. (“Longer” here means tending closer one second than to .3 seconds.)
- The variance in the Energy during the cooling period seems to be greater than at the beginning.
- Over time, the level of Energy appears to remain in a Cooling Down state for longer and longer.
- In at least one instance, the Zapper goes from a Cooling Down state back up to a Somewhat Hot state before returning to a Cooling Down state.
- Starting from about the middle of the observed period, the Zapper appears many times not to reach the Cool state at all.
As I’m observing these results, two questions are looping in my mind. The first is “Is there a problem here?” The second is “Is my client okay with all this?”
When I see the inconsistency of the results, I experience a vague feeling of unease and confusion, followed by feelings of curiosity. The curiosity is about the product’s behaviour, but it’s also about why I feel uneasy and confused. Notice that my feelings and mental models are internal, tacit, and private, at the moment I have them. If I want to make sense of the relationships between my observations and my feelings, I have to do some detective work; feelings don’t come with return addresses on them.
I pause for a moment, and quickly consider: the cooldown period is not the same every time.
I make an inference that that could be a problem, since we typically desire a product’s behaviour to be consistent with itself. Is there a problem here? I wonder if the product has shown a consistent, stable cooldown pattern in the past. If it has, it’s not doing that now.
I make an inference that product might be inconsistent with its history. Is there a problem here? There’s a related inference: all other things being equal, we desire a product to be consistent with its history, so an inconsistency with its history would point to a possible problem.
Another inference: there may be a document that makes a claim about the behaviour required to fulfill the desire of some important person. Inconsistency with that document (a reference; a medium that extends communication and expression of desire) could represent a problem, since (by inference) inconsistency with the client’s desire would probably be a problem too. I don’t have a copy of such a document. Is my client okay with that?
Is there a document of that nature? Where is it? Who wrote it? Whose desires are being represented? Can I confer with those people; that is, can I have conference with them? If I can’t, the quality and relevance of my analysis will be compromised. Is my client okay with that?
Since this is a medical device, is there a standards document (a reference) to which it should conform? I don’t know; in order to sort that out, I might have engaged in conference with a domain expert who is aware of such things. The expert is also a medium, extending my capacity to know about the domain, and the desires of people in that domain.
I might have to examine a reference and engage in conference to find another relevant reference, or to understand it.
If I pay attention, I notice that Excel (and its conditional formatting feature) are media too, extending my capacity to observe patterns in the behaviour of the Zapper Box. The image I’m looking at is a reference.
The test rig hooked up to the Zapper Box is also a medium, a reference, enabling testers’ capacity to observe the amount of Energy at the electrode. The test rig’s log is a medium to which I can refer, providing a record of precise observations that I can analyse over the longer term.
The Control Box also includes testability features that produce a log (yet another reference). Those features extend the testers’ capacity to record the actions of the control box, and the log enables the comparison between the test rig’s log and the operator’s intended actions. There is a whole network of references here. I could apply consistency oracles to all of them, singly and in combination.
My curiosity is also aroused by questions about the test. Did the testers follow the same protocol on each test run? Was the Zapper Box powered on for the same amount of time before the tester flipped the switch at the Control Box? Did the measurement start exactly when the Zapper Box was told to turn off? Was the connection between the Control Box and the Zapper Box reliable? How would we know? Did the testers allow the Zapper Box to cool down between test runs? For how long? For the same amount of time each time? Is the test rig measuring the Energy properly? How would we know?
Notice: although there has been extensive use of tools, no checking has occurred here! James and the testers tested the product, gathered data, and presented that data in a form that allowed them (and others) to see interesting patterns. I have been analyzing those patterns (and I hope you have too).
Some oracles just provide us with “pass or fail”, “true or false”, “green or red” results. Other oracles point us to possible problems upon which we may shine light. In this case, we would need more information—more references, more tools, more conference—before we could determine more clearly whether there is a problem. We might or might not need any of these things before the client could decide that there is a problem. More significantly, we would need more information to determine how we might be able to check for a problem. We must apply informal oracles before we can learn how to apply formal oracles well.
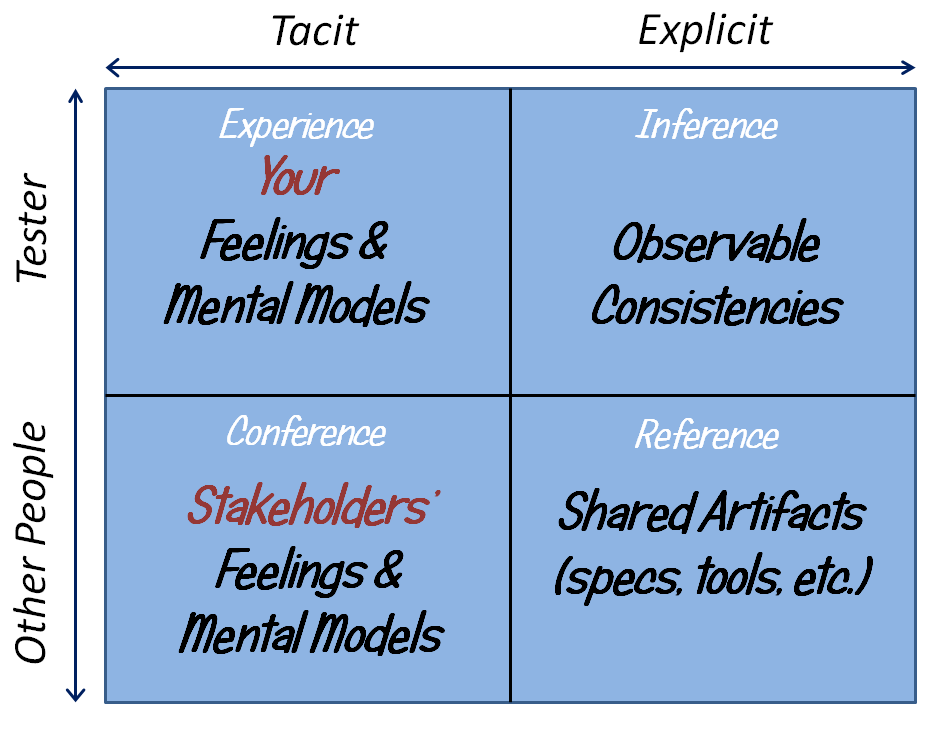
In other words: the process of recognizing a problem sometimes requires us to travel all over the oracle quadrants. That’s far more than “trying the product and comparing it to the specification”.
All this sets us up for the next few posts: if we considered the oracle principles (themselves media for recognizing problems that threaten people’s desires!), how could we imagine applying tools to enable, extend, enhance, accelerate, or intensify our capabilities as testers? What other roles might oracles play in the process? And if we are to use oracles and tools wisely, what effects—good and bad—could we anticipate from applying them? As we shape our tools, how might our tools shape us?
The first part of an answer is in the next post in this series.
[…] Blog: Oracles from the Inside Out, Part 6: Oracles as Extensions of Testers – Michael Bolton – http://www.developsense.com/blog/2015/09/oracles-from-the-inside-out-part-6-oracles-as-extensions-of… […]
[…] Part 6: Oracles as Extensions of Testers […]